API version 2013-01-01 of Amazon CloudSearch is internally powered by customized version of Apache Solr Engine, and it is specifically designed for running highly scalable and available search on Amazon Web Services Cloud. This 2013 CloudSearch API has lots of similarities with Apache Solr and customers can easily migrate to this version and leverage the benefits of Amazon Cloud Infrastructure. We are already hearing many AWS customers are planning their migration from FAST, Solr and A9 Engine into the Amazon CloudSearch - 2013-01-01 API engine.
My team is already migrating couple of customers into this Amazon CloudSearch 2013-01-01 API and i have shared our experience on this process for the benefit of AWS community.
Reference Migration Architecture and requirements:
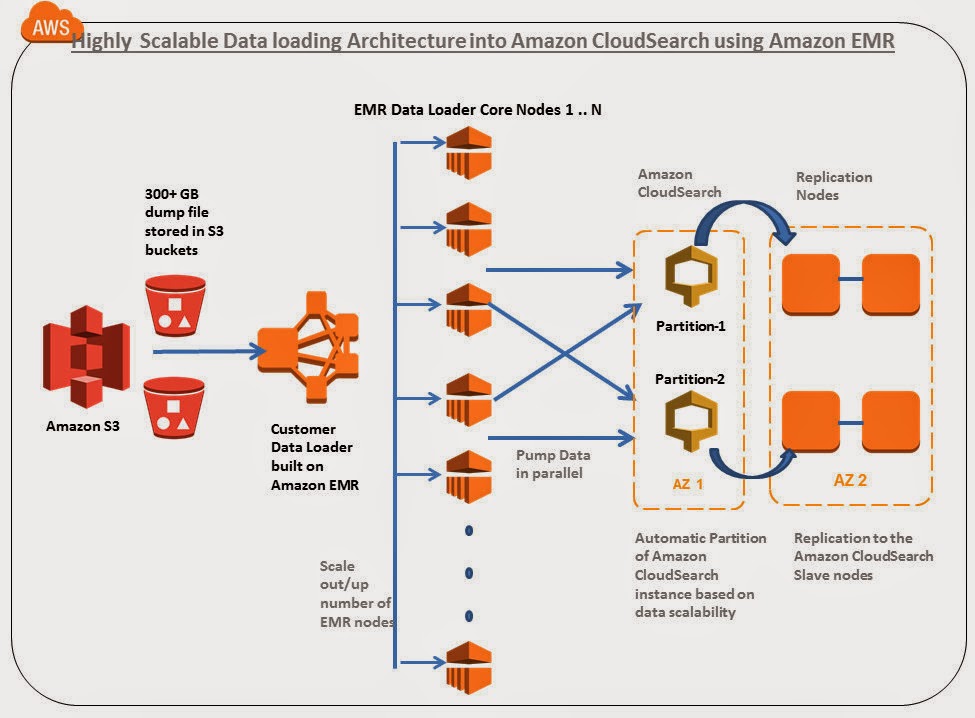
In this article i am going to explore how to
- Migrate a 300+ GB index containing close to 247+ million records distributed in 105 searchable fields in a highly scalable /parallel manner in AWS infrastructure.
- 300 + GB index file is stored in Amazon S3
- Custom Data loader program built on Amazon Elastic MapReduce is used for parallel loading
- Around ~6 Search.M2.2Xlarge are created with 2 partitions and 5 replication count
- Around 10+ M1.large EMR Core nodes are for Data loading. This loader can be increased to hundreds of nodes depending upon the volume and velocity of data pump required.
- Amazon CloudSearch Infrastructure provisioning, Automated partitioning, replication count are handled by AWS.
Lets get into the details below:
Step 1)Create a new Amazon CloudSearch Domain: We have named the search domain as "bigdatasearch" and chose the search instance type as search.m2.2xlarge. Since we are planning to pump and query a 300 GB index with millions of document, it did not make sense for us to chose a smaller instance type of Amazon CloudSearch. Usually the base instance type can be selected based on the number and size of the documents you are planning to maintain in the Amazon CloudSearch.
Note: Here we have chosen replication count as 5. This is little strange in a distributed architecture because usually more replication count for the master decreases the speed of document upload. But when we were playing with Amazon CloudSearch we observed that it is increasing the speed of uploads. In addition we also observed the following :
- If we keep the replication count 0 or less, use a smaller search instance type and pump documents in parallel from multiple nodes, either the Amazon CloudSearch Server is failing sometimes or error rates are high.
- If we keep the replication count 0 or less , use a larger search instance type and pump documents in parallel from multiple nodes, internally Amazon Cloud Search itself is creating 3-5 nodes and it shows in the replication count. Waiting to discuss with AWS SA folks on this behavior.

We will be utilizing distributed uploading technique which we custom built using Amazon Elastic MapReduce to pump data to the Amazon CloudSearch server. This technique enables us to write more Index data in parallel.

Next step is to Add index fields to create your Amazon CloudSearch Schema configuration.
Step 3)Adding Amazon CloudSearch Index Fields: Once all the fields have been configured in the schema, click on continue button. In the schema file used we have 100+ fields to be indexed for this particular search domain.

Step 4) Review the setup configurations and launch:
We have 100+ Index fields with scaling options instance type as m2.2xlarge and replication count 5 in the "bigdatasearch" domain.
We have 100+ Index fields with scaling options instance type as m2.2xlarge and replication count 5 in the "bigdatasearch" domain.

Step 5 ) Wait till the Amazon CloudSearch Infrastructure is provisioned for you on the back. Usually it takes 10 minutes, it will also list if there is any error encountered when creating the index fields.

Once the Amazon CloudSearch infrastructure is provisioned at the back end , you should notice the "bigdatasearch" domain is "Active". The search and Document endpoints are published and currently no of searchable document is "0". There is only 1 CloudSearch Index Partition (Shards) and 5 search.m2.2xlarge instances.

Step 6)Configuring Synonyms: We have 2+ MB of Synonyms which needs to be configured into the Amazon CloudSearch domain. For this, we used Cloud Search cli-toolkit to upload synonyms to Cloud Search.
cs-configure-analysis-scheme -d bigdatasearch --name customanalysisscheme --lang en -e cloudsearch.ap-southeast-1.amazonaws.com --synonyms customsynonyms.txt
Since the volume of index data is huge (300+ GB) we have created a Custom Data Loader built on Amazon Elastic MapReduce to pump the data in parallel into Amazon CloudSearch. Since it is built on Amazon Elastic MapReduce, we can use the same program without modification for scale to upload TB's of index into the search system with hundreds of Data loader EMR core/task nodes.
Step 7) Create Amazon Elastic MapReduce Data Loader Cluster Configuration:

Step 8) Configure the Elastic MapReduce (EMR) Capacity: We are using 10 M1.Large core node instances for uploading the data from inside AWS VPC. Depending upon the Data size (GB->TB) and Upload hours we can increase the EMR core nodes capacity and number to speed up the data pump (upload) process.

To know more about How Spot instances can save cost on Amazon EMR ? refer URL AWS Cost Saving Tip 12: Add Spot Instances with Amazon EMR
Step 9)Add Custom data loader program Jar to EMR:
We have exported the data from a MSSQL server as flat UTF-8 dump file and stored it in Amazon S3. We are giving the 300+ GB Dump file as the input for the Amazon EMR CloudSearch Data Loader program to upload into Amazon CS in parallel. Buckets configurations of the Data Loader jar, Input, output and log files are configured in this screen
We have exported the data from a MSSQL server as flat UTF-8 dump file and stored it in Amazon S3. We are giving the 300+ GB Dump file as the input for the Amazon EMR CloudSearch Data Loader program to upload into Amazon CS in parallel. Buckets configurations of the Data Loader jar, Input, output and log files are configured in this screen

Step 10) Configure Amazon CloudSearch Access Policies: We need to open Cloud Search security group access policies to accept upload requests from EMR cluster inside VPC. Configure static IP’s of all the instances or IP range of the data loader clients

Step 11)Run the Amazon Elastic MapReduce Data loader job :

Step 12) Analyzing the Amazon EMR Data loader Job Output:
Output of the JOB can be seen in the AWS EMR JOB logs. Here are few details:
Output of the JOB can be seen in the AWS EMR JOB logs. Here are few details:
- “Map output records” in the log tells how many records are inserted into the Amazon CloudSearch , we can observe close to 247,681,520 documents(247+ million) are pumped.
- “Bytes Read” in the output tells what is size of data set which the JOB has read. We can observe 322387978332 bytes which is equivalent to 300+ GB of index in the Amazon CloudSearch
- The entire pumping process took ~30 hours with 10 m1.large core nodes for us. We observed that increasing the number of Data loader EMR nodes or their capacity improves the upload speed drastically.

Step 14) Analyzing the CloudSearch Dashboard :
We observed that it takes some time for cloud search to reflect actual count of the indexed documents.
After the pumping of 300 + GB index you can observe that currently 2 Amazon CloudSearch partitions ( shards) are used to distribute 247+ million documents with 100+ index fields. This is tremendous cost savings compared to A9 powered Amazon CloudSearch. Amazon CloudSearch has automatically created shards based on the volume of data pumped in to the system. This is cool !!!, it reduces the maintenance headache of the infra admins. If the Amazon CloudSearch team can make this partition concept as configurable parameter in future it will be useful.

Step 15) Executing a Sample Search queries: We are executing a some sample product search queries on the "bigdatasearch" domain to check whether everything is fine. Distributed query was fired and Results came Sub Second from one of the partitions.

In short, It is cost effective compared to old A9 powered CloudSearch, Automated scaling of replication counts for request scalability, automated scaling of partitions for data scalability relieves the infra admin headaches, strong apache Solr pedigree and its long list of feature additions in coming months will make it more interesting.
After working with this service few weeks, we feel it is going to become the major search service on AWS in coming years, giving tough fight for Apache Solr and ElastiSearch deployments on EC2.
This article was co authored with Ankit @8Kmiles.
No comments:
Post a Comment